freud.locality.Filter¶
In this notebook, we introduce the neighborlist filter concept, discuss the filtering methods implemented in freud, and demonstrate how to use them with good efficiency.
What is a NeighborList Filter?¶
A neighborlist filter is a class which removes some bonds from a pre-defined neighborlist. A neighborlist filter can be thought of as a function for which an unfiltered NeighborList is given as the input and a filtered version of the input NeighborList is the output. Freud already has some methods in the NeighborList class like filter and filter_r which can achieve this concept, but often the full system definition is needed to decide which bonds to remove. This is often the
case when typical neighbor finding algorithms which use r_max or num_neighbors label two particles as neighbors even though they are blocked by another particle in between them. Each of freud’s neighborlist filters defines the concept of “blocking” or being “blocked” differently and removes bonds between particles which are blocked by another particle.
The freud library’s neighborlist filter algorithms are the same as some well-known parameter-free neighbor finding methods like the Solid Angle Nearest Neighbor (SANN) method and the Relative Angular Distance (RAD) method. Each of these neighbor finding methods was created to find a set of neighbors in which no neighbor is blocked by any other neighbor. In that sense, freud’s neighborlist filters can be used to find neighbors as well as to filter neighbors. The difference between finding and filtering depends solely on the meaning attributed to the unfiltered neighborlist.
The following sections give descriptions of the algorithms used by each neighborlist filter in freud along with code examples which illustrate proper usage.
The Solid Angle Nearest Neighbor (SANN) Method¶
With the Solid Angle Nearest Neighbor (SANN) method, we look for enough nearby neighbors to fully occupy the \(4 \pi\) solid angle distribution surrounding a particle and label all neighbors further away as blocked. Strictly speaking, we consider neighbors of a particle \(i\) to consist of the nearest (i.e., closest) \(m\) particles \({j}\) in neighborhood defined by shell radius \(R_i^{(m)}\) such that the sum of their solid angles associated with \(\theta_{i,j}\) equals \(4 \pi\) :
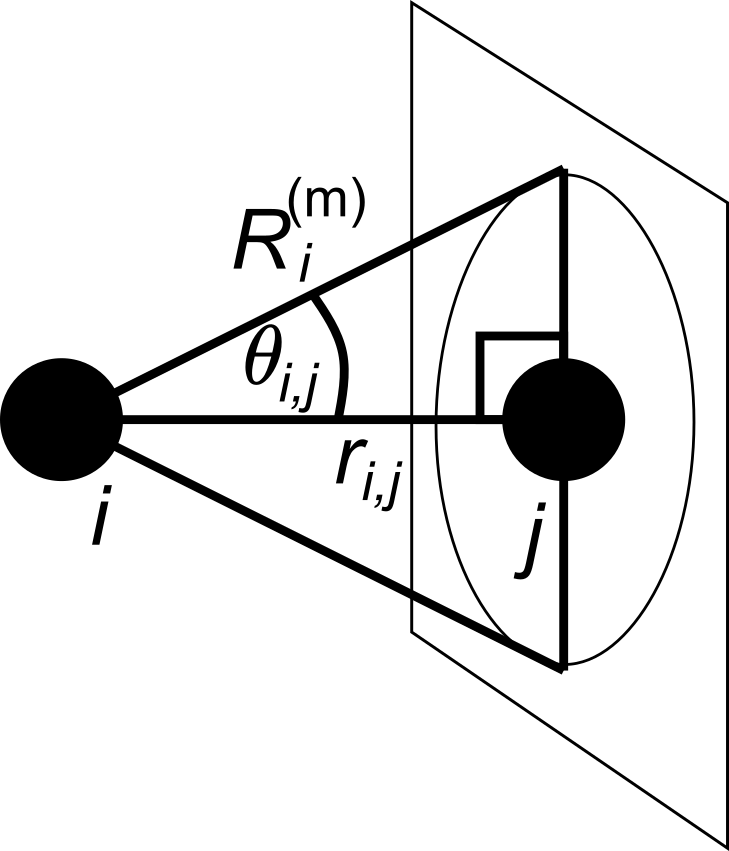 The
The freud.locality.FilterSANN class implements this method, and an example usage is shown below:
[1]:
import freud
# make the system to operate on
N = 1000
L = 10
box, points = freud.data.make_random_system(L, N, seed=10)
# create the unfiltered neighborlist
nlist = (
freud.locality.AABBQuery(box, points)
.query(points, dict(r_max=4.9, exclude_ii=True))
.toNeighborList()
)
# make the FilterSANN and call compute
sann = freud.locality.FilterSANN(allow_incomplete_shell=True)
sann.compute((box, points), neighbors=nlist)
# access the filtered neighborlist as a property at the end
sann.filtered_nlist
[1]:
<freud.locality.NeighborList at 0x7f3671512840>
Instead of having to do the neighbor query explicitly in your python script, freud will do it automatically if query arguents are passed to the neighbors argument of the filter’s compute method. The following call to compute is equivalent to the call in the previous script:
[2]:
# call compute
sann.compute((box, points), neighbors=dict(r_max=4.9, exclude_ii=True))
# get the filtered neighborlist at the end
sann.filtered_nlist
# get the unfiltered neighborlist automatically computed by freud
sann.unfiltered_nlist
[2]:
<freud.locality.NeighborList at 0x7f371c162600>
Custom NeighborList’s are also supported as inputs to the neighbors argument, as shown below:
[3]:
import numpy as np
# custom neighborlist
M = 15
query_point_indices = np.arange(N).repeat(M)
point_indices = np.random.randint(low=0, high=N, size=M * N)
vectors = box.wrap(points[point_indices, :] - points[query_point_indices, :])
nlist = freud.locality.NeighborList.from_arrays(
N, N, query_point_indices, point_indices, vectors
)
# call compute
sann.compute((box, points), neighbors=nlist)
# get the filtered neighborlist at the end
sann.filtered_nlist
[3]:
<freud.locality.NeighborList at 0x7f371e34fa80>
If nothing is given to the neighbors argument, freud will automatically compute an all pairs neighborlist (excluding ii pairs) as the unfiltered neighborlist, equivalent to what is shown below:
[4]:
# make all pairs neighborlist with ii pairs excluded
nlist = freud.locality.NeighborList.all_pairs((box, points))
# call compute
sann.compute((box, points), neighbors=nlist)
# get the filtered neighborlist at the end
sann.filtered_nlist
[4]:
<freud.locality.NeighborList at 0x7f36707510c0>
The Relative Angular Distance (RAD) Method¶
With the Relative Angular Distance (RAD) method, we label a neighbor as blocked if the angle formed between it, the other neighbor, and a blocking particle is less than a given threshold. Strictly speaking, we begin by considering neighbors of particle \(i\) starting with the closest neighbor and going radially outward. We label a potential neighbor \(j\) blocked by a nearer neighbor particle \(k\) if
where \(r_{\alpha \beta}\) is the distance between particles \(\alpha\) and \(\beta\) and \(\theta_{jik}\) is the angle centered at particle \(i\) extending out to particles \(j\) and \(k\).
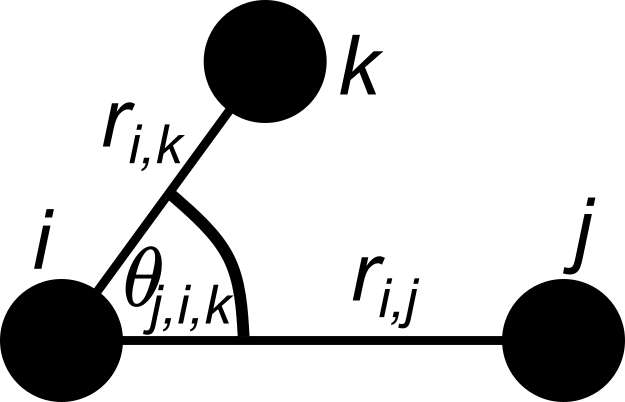
There are two variants of the RAD method: RAD\(_{open}\) and RAD\(_{closed}\). In RAD\(_{closed}\), we consider all neighbors further away than the first blocked neighbor \(j\) to also be blocked. In other words, the RAD\(_{closed}\) algorithm terminates the search for neighbors of particle \(i\) and begins the search for neighbors of particle \(i+1\) after it finds the first blocked neighbor of particle \(i\). In RAD\(_{open}\), we consider all
neighbors regardless of whether or not closer neighbors are blocked. The flag determining which RAD algorithm we use is controlled by the terminate_after_blocked argument to the FilterRAD constructor, as shown below:
[5]:
# default behavior is RAD closed
rad_closed = freud.locality.FilterRAD()
# RAD open
rad_open = freud.locality.FilterRAD(terminate_after_blocked=False)
All patterns in the compute method established in the previous section for the FilterSANN class also apply to the FilterRAD class.
Incomplete Shells and Performance Considerations¶
There are two more issues to discuss in this tutorial related to the input unfiltered neighborlist.
In cases where the input neighborlist is sparse (i.e. relatively few neighbors), there may not be enough neighbors in the unfiltered neighborlist such that each particle has the proper number of neighbors in the filtered neighborlist according to the SANN (RAD) algorithm. In these cases it is impossible for FilterSANN (FilterRAD) to return a full SANN (RAD) neighborlist and we say those particles have “incomplete shells”. The FilterSANN (FilterRAD) class will by default throw an
error message detailing which particles do not have full neighbor shells. An example is shown in the code block below:
[6]:
# sparse system
N = 5
L = 100
system = freud.data.make_random_system(L, N)
# try to compute SANN neighborlist
sann = freud.locality.FilterSANN(allow_incomplete_shell=True)
try:
sann.compute(system)
except RuntimeError as e:
print(e)
Query point indices 0, 1, 2, 3, 4 do not have full neighbor shells.
This error can be downgraded to a warning through an optional argument allow_incomplete_shell to the filter class’s constructor, as shown in the cell below. When downgraded, particles with incomplete shells will have the same number of neighbors in the filtered neighborlist as they had in the unfiltered neighborlist.
[7]:
sann = freud.locality.FilterSANN(allow_incomplete_shell=True)
sann.compute(system)
[7]:
<freud.locality.FilterSANN at 0x7f371e352520>
WARNING: Query point indices 0, 1, 2, 3, 4 do not have full neighbor shells.
In cases where the input neighborlist is dense (i.e. \(\approx N\) neighbors per particle), the filtering done by FilterSANN and FilterRAD can take a long time to complete and often most of the input neighbors will be blocked. To use these classes more efficiently, physical intuition about the system can be used to limit the number of neighbors in the unfiltered neighborlist. For example, plotting a \(g(r)\) for the system and choosing an r_max slightly larger than fist peak
distance can be used as a good starting point. Another option which does not rely on any physical intuition is to start with a small number of neighbors, and slowly increase the number until the filter class does not issue a RuntimeError. An example demonstrating this method is shown below:
[8]:
# dense system
N = 1000000
L = 10
system = freud.data.make_random_system(L, N)
# start with a small number of neighbors
num_neighbors = 4
all_shells_full = False
rad = freud.locality.FilterRAD()
# iterate and increase num_neighbors each time
while not all_shells_full:
print("number of neighbors:", num_neighbors)
try:
rad.compute(system, dict(num_neighbors=num_neighbors, exclude_ii=True))
all_shells_full = True
except RuntimeError:
num_neighbors += 1
number of neighbors: 4
number of neighbors: 5
number of neighbors: 6
number of neighbors: 7
number of neighbors: 8
number of neighbors: 9
number of neighbors: 10
number of neighbors: 11
number of neighbors: 12
number of neighbors: 13
number of neighbors: 14